Automatizando analises documentais na Bolsa do Brasil
Contexto
A UIF (Unidade de Infraestrutura para Financiamentos) é uma plataforma voltada para instituições financeiras, especializada no registro de garantias de veículos automotores e operações de crédito.
Entre muitos serviços, há as operações de cancelamento de gravames, realizadas para quando o documento do veículo ainda não foi emitido. Em alguns Estados, há a necessidade de solicitar um desbloqueio para esta operação.
Com um alto volume anual, as solicitações de desbloqueio de cancelamento eram processadas manualmente, uma a uma.
Problema
Com 18 motivos de desbloqueio e documentos variados por caso, a operação escalava em pessoas, não em eficiência. O objetivo era inverter isso construindo um agente capaz de apoiar a operação nos casos de maior volume.
A solução devia atender dois perfis com problemas distintos:
sobrecarga repetitiva, dados analisados sem hierarquia de leitura
upload fragmentado dos documentos necessários
Processo e decisões
Para descobrir como os documentos eram lidos e validados na prática me reuni com 3 operadores responsáveis pela operação.
O grupo focal revelou uma preferência clara por visualização dos dados em tabela, desvios de análise causados por falta de clareza nos dados apresentados, e a recorrência de dados validados repetidamente entre documentos (validação cruzada).

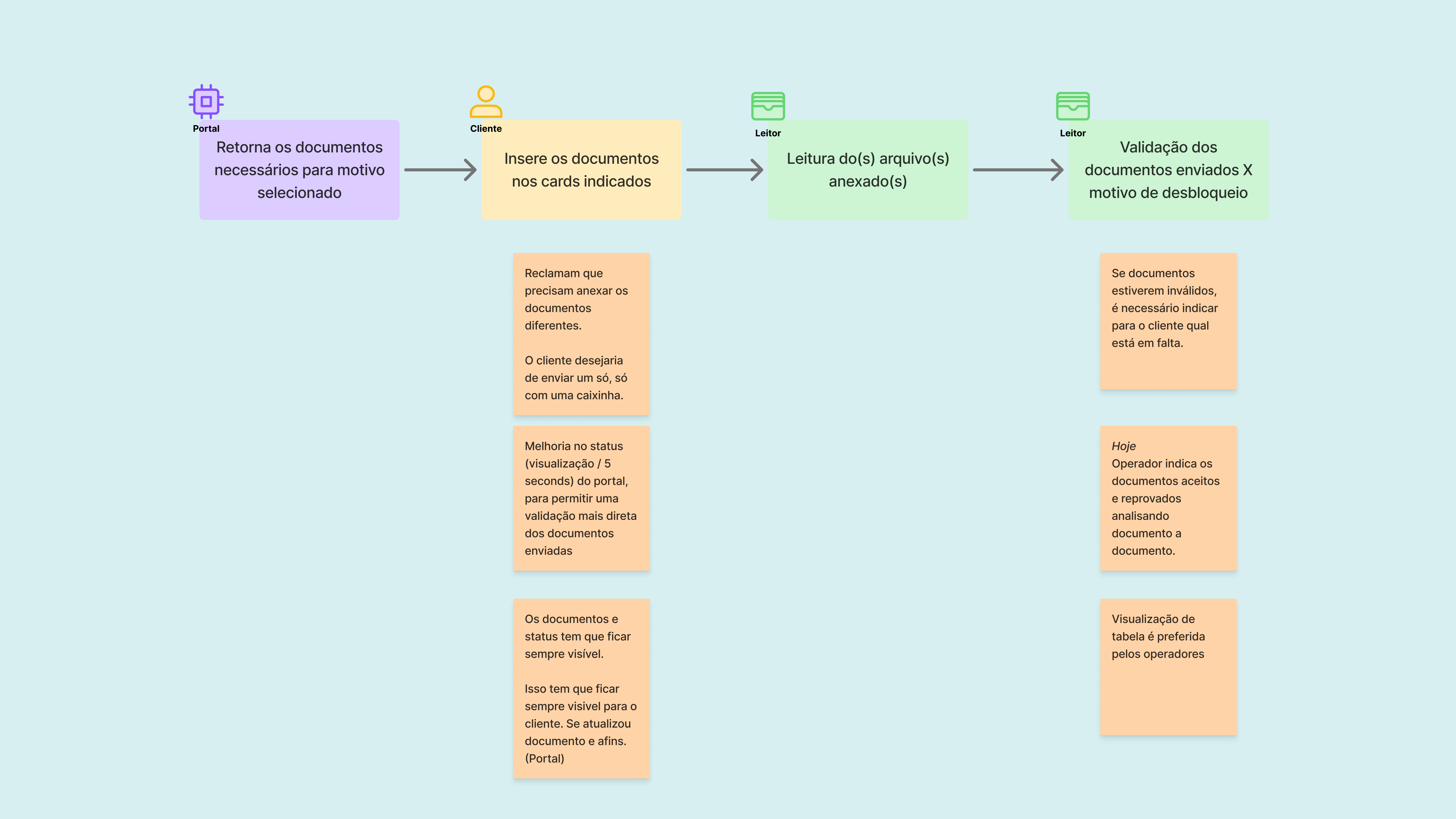
Para levantar cada etapa do processo existente, me reuni com o time B3 em uma sessão conjunta em quadro branco.
Com base no mapa, adicionei pontos de atrito e oportunidades de melhoria a partir de três fontes: brainstorming com stakeholders (com conhecimento tácito e feedbacks dos clientes reais), análise do design atual e respostas do grupo focal com operadores, estabelecendo a base para as decisões que vieram depois.
Alguns dos insights foram:
O cliente desejaria enviar os documentos em uma só "caixinha"
Quando o chassi não estiver apto para seguir com o processo, pode haver uma explicação mais clara do motivo.
Para análise documental facilitada, é essencial comparar os dados esperados com os extraídos, indicando se está correto ou não.
Depois do problema mapeado, foi necessário realizar uma priorização. Ao todo, foram 9 motivos priorizados, que cobriam +90% do volume anual.
Mesmo com os motivos priorizados, o volume de documentos ainda era grande (27). Resolvi analisar então os dados extraídos de cada documento, essa análise me permitiu agrupar documentos por afinidade de dados, e não por tipo.
O agrupamento permitiu reduzir de ~20 para 7 prompts de análise documental, diminuindo variação e ambiguidade tanto para o agente, e agilizando o desenvolvimento para o MVP.
Desenhando para o Agente
O agente precisava operar como um colaborador paralelo com responsabilidade sobre dados extraídos do documento, o que exigiu pensar a interação além da interface visual.
Os grupos de documentos e dados (clusters) reduziram ambiguidade de prompt e alucinação de output, funcionando como restrições de design para o comportamento do agente.
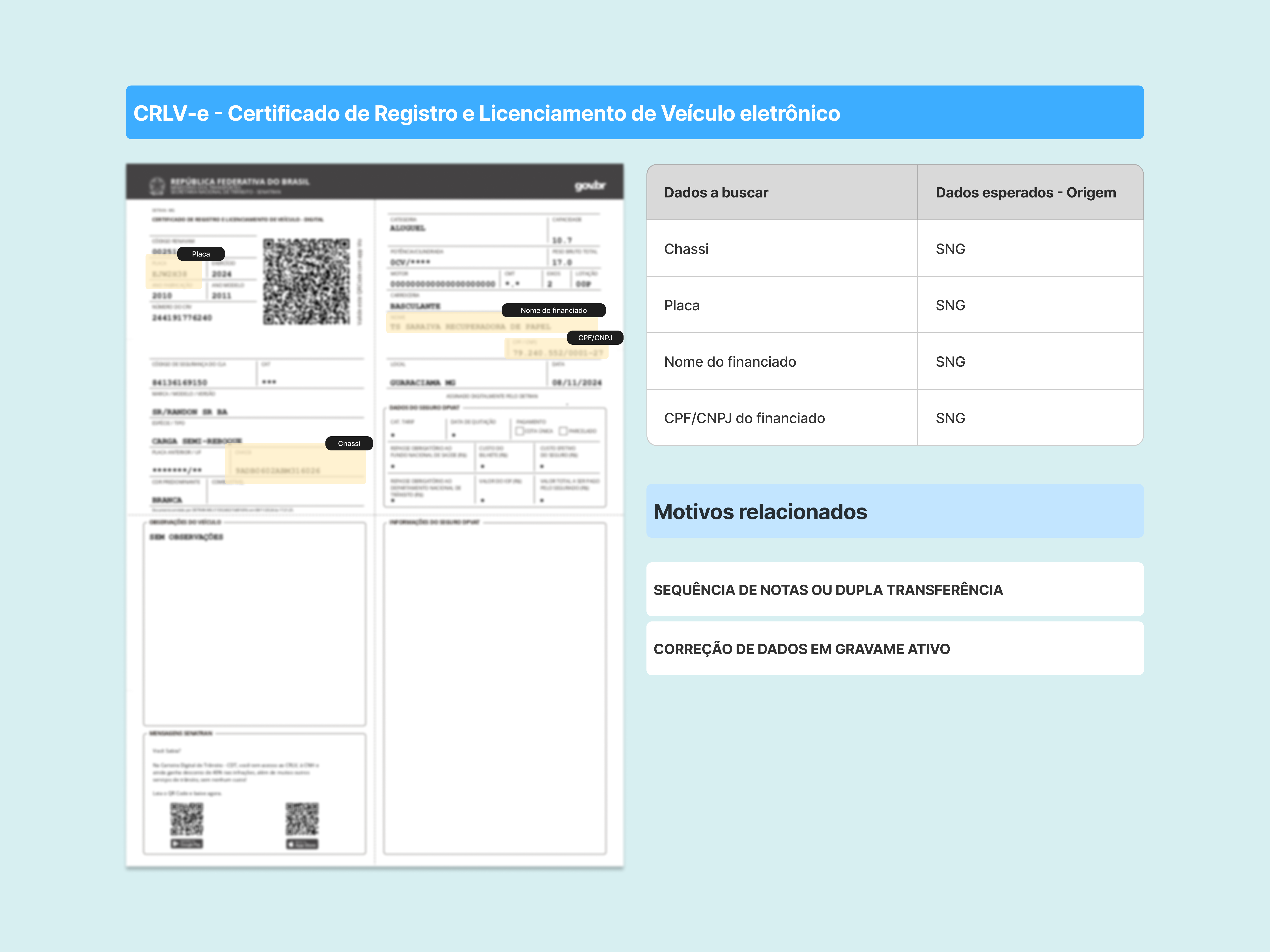
Também defini quais campos extrair, em que ordem apresentar, e quais inconsistências sinalizar para os operadores.
Para os campos, também era necessário entender de onde seriam extraídos os resultados esperados. Realizei, com apoio do time B3, uma análise do processo de abertura no portal, identificando quais dados seriam possíveis de serem coletados no momento da abertura e quais seriam necessárias a consulta no Sistema Nacional de Gravames (SNG)
Alguns campos, entretanto, precisariam ser cruzados com os dados extraídos de outros documentos (validação cruzada).
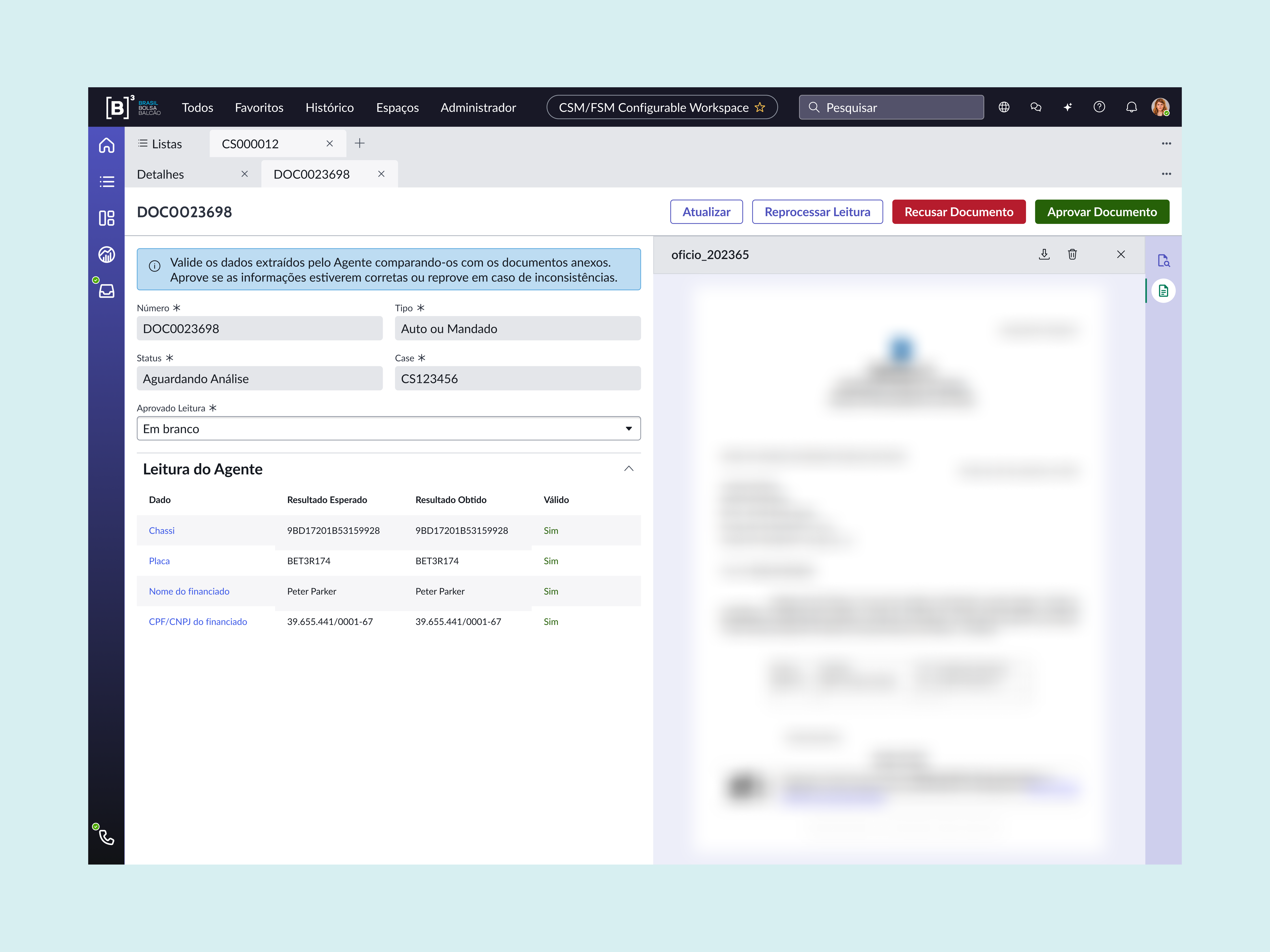
O representante legal do requerimento deve coincidir com o da procuração da empresa. Isso permite avaliar automaticamente se o agente acertou na extração e análise, capturar o feedback do operador como sinal de qualidade, e eliminar a necessidade de analisar linha a linha, focando apenas nas divergências sinalizadas.
| Campo | Res. esperado (Origem) | Res. obtido | Análise do Agente |
|---|---|---|---|
| Representante | Peter Parker (Procuração) | Peter Parker | Acerto |
| Placa | BET3R174 (SNG) | BET3RI74 | Placa divergente |
| Chassi | 5XXAM2tgwu9fm0285 (SNG) | Não encontrado | Dado ausente |
Solução
Considerei desde o início as limitações de customização da plataforma da ServiceNow. Layout, hierarquia de informação e interações foram desenhados dentro do que o ambiente permitia, não contra ele.
Para os operadores, foi entregue a preferida visualização em tabela, dados agrupados e ordenados de maneira lógica e checagem cruzada com justificativa quando divergente.
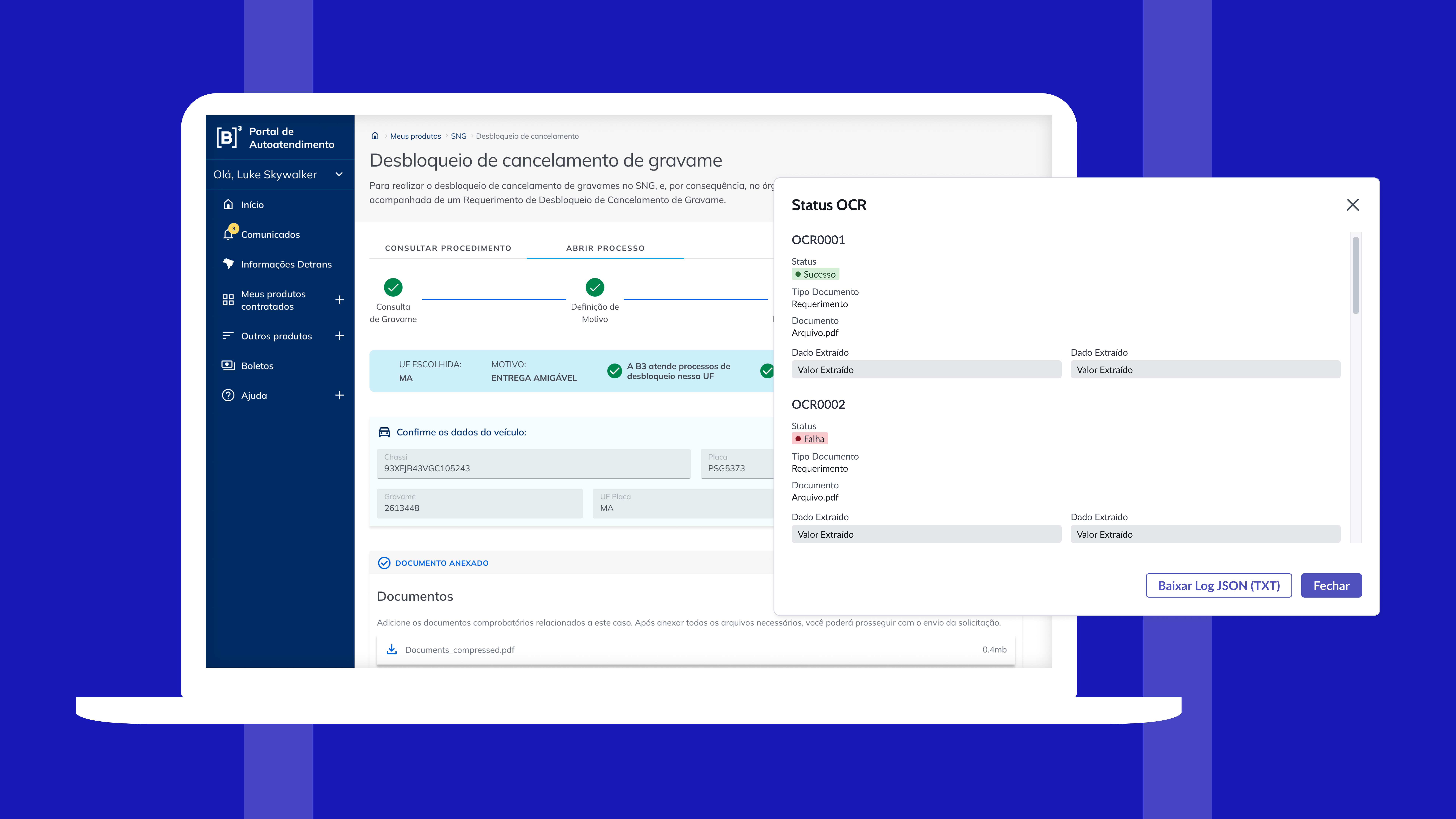
Durante o uso do MVP, os operadores relataram uma dor que não foi identificada no discovery: a espera sem feedback do Agente. Assim desenhei o layout para acompanhamento do status do OCR, que permite acompanhar o processamento da leitura e, no fim, os dados extraídos são apresentados em uma modal, permitindo auditória quando necessária.
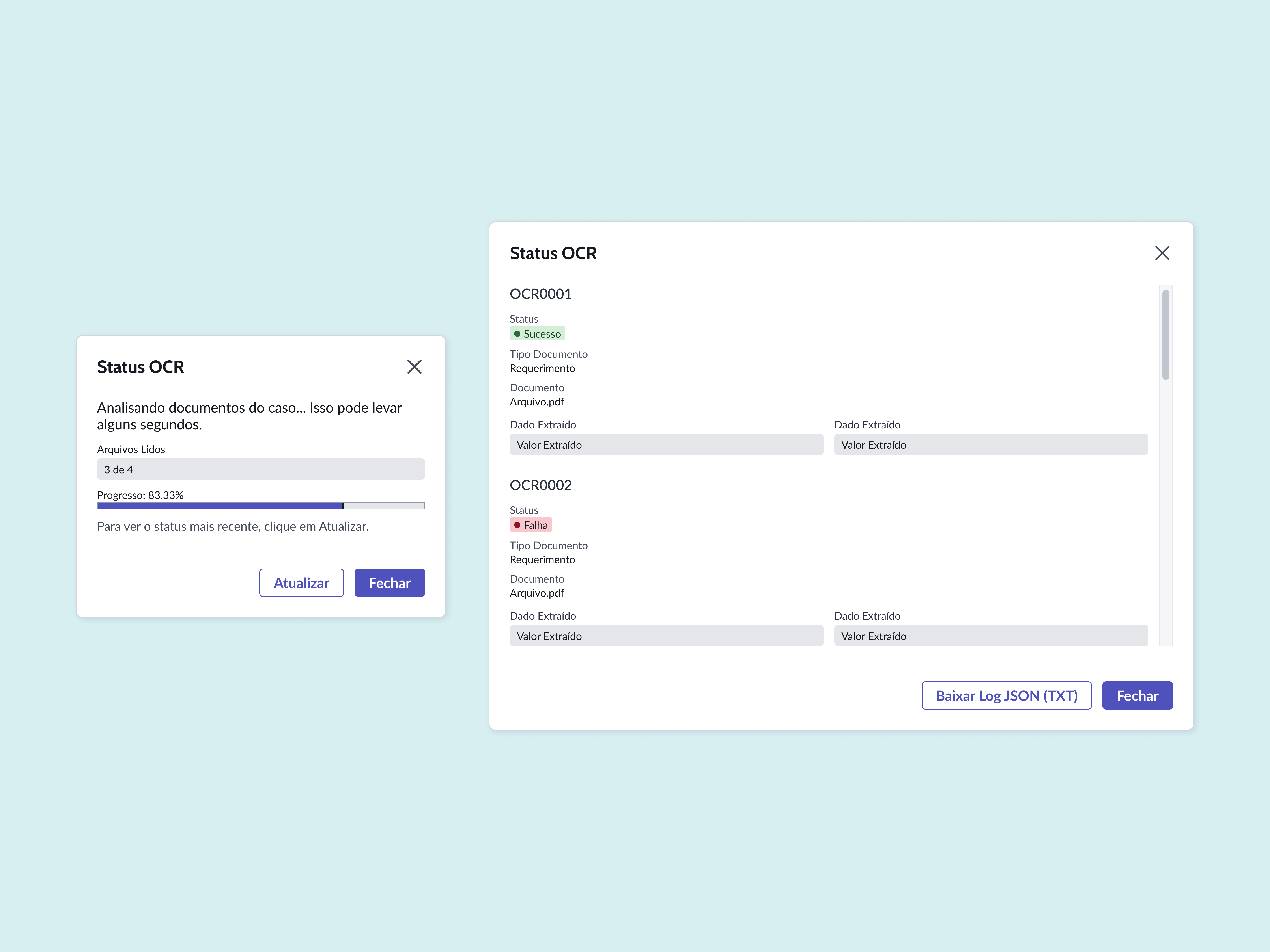
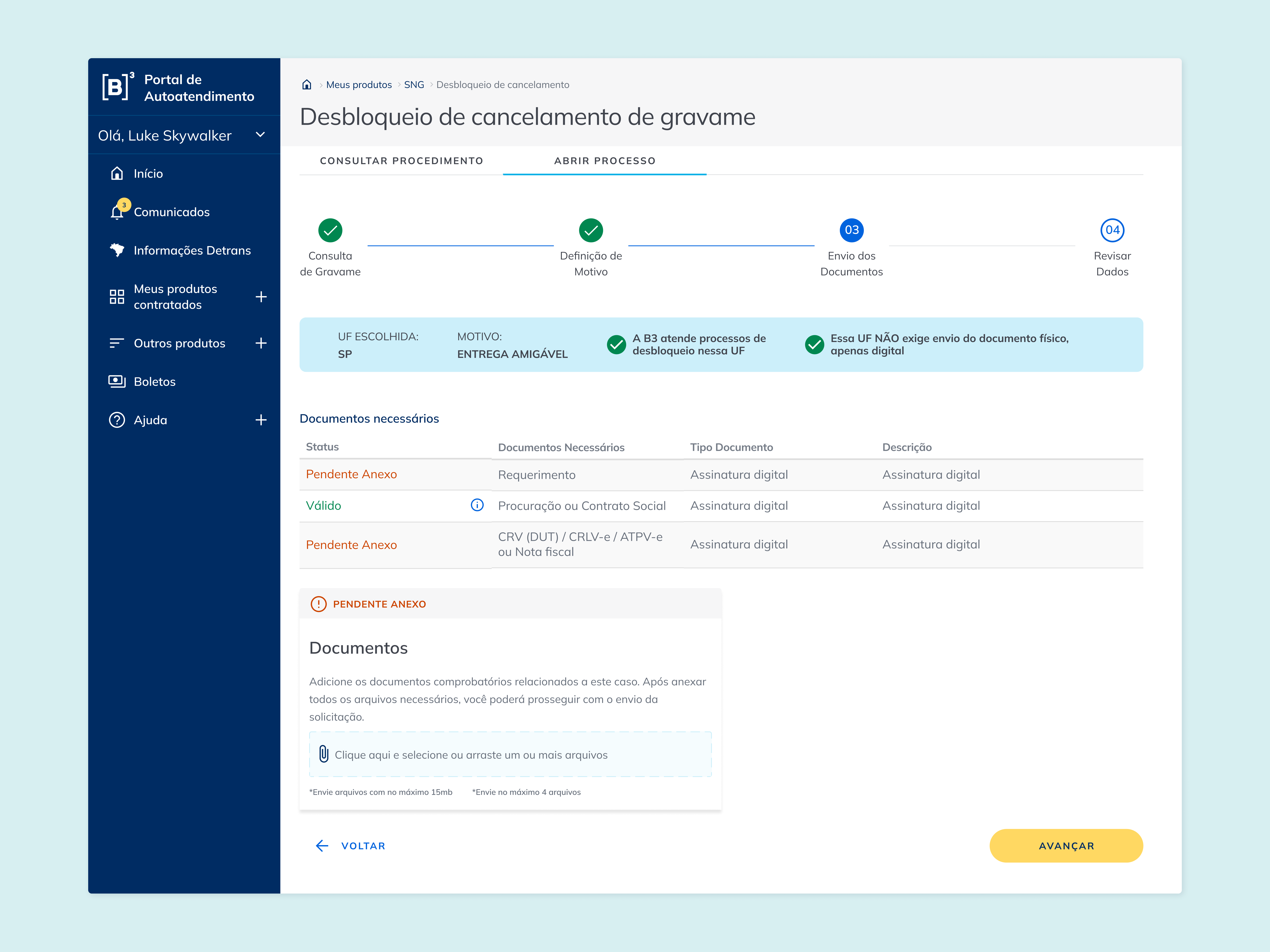
Para os clientes, a adição de um stepper de 4 etapas, mensagem de bloqueio com motivo explícito, e upload consolidado em campo único.
Resultados e aprendizados
na extração de dados
por caso
Operadores na prototipação mais cedo: a preferência por tabela era clara desde o discovery, mas validar variações de densidade de informação antes dos testes teria economizado um ciclo de refinamento.
Sessões de Mágico de Oz: simular o comportamento do agente com operadores reais antes do desenvolvimento teria revelado dados ausentes no mapeamento e campos marcados como obrigatórios que, na prática, não eram. Chegaria ao desenvolvimento com prompts mais precisos e menos retrabalho.
Volume concorrente no mapeamento: a necessidade de 4 filas de leitura só ficou evidente durante os testes; um olhar para o throughput esperado teria antecipado esse gargalo na fase de arquitetura.